0、gRPC
gRPC 是一个高性能、开源、通用的RPC框架,由Google推出,基于HTTP/2协议标准设计开发,默认采用Protocol Buffers数据序列化协议,支持多种开发语言。gRPC提供了一种简单的方法来精确的定义服务,并且为客户端和服务端自动生成可靠的功能库。
gRPC 提供 protocol buffer 编译插件,能够从一个服务定义的 .proto 文件生成客户端和服务端代码。通常 gRPC 用户可以在服务端实现这些API,并从客户端调用它们。
- 在服务侧,服务端实现服务接口,运行一个 gRPC 服务器来处理客户端调用。gRPC 底层架构会解码传入的请求,执行服务方法,编码服务应答。
- 在客户侧,客户端有一个存根实现了服务端同样的方法。客户端可以在本地存根调用这些方法,用合适的 protocol buffer 消息类型封装这些参数— gRPC 来负责发送请求给服务端并返回服务端 protocol buffer 响应。
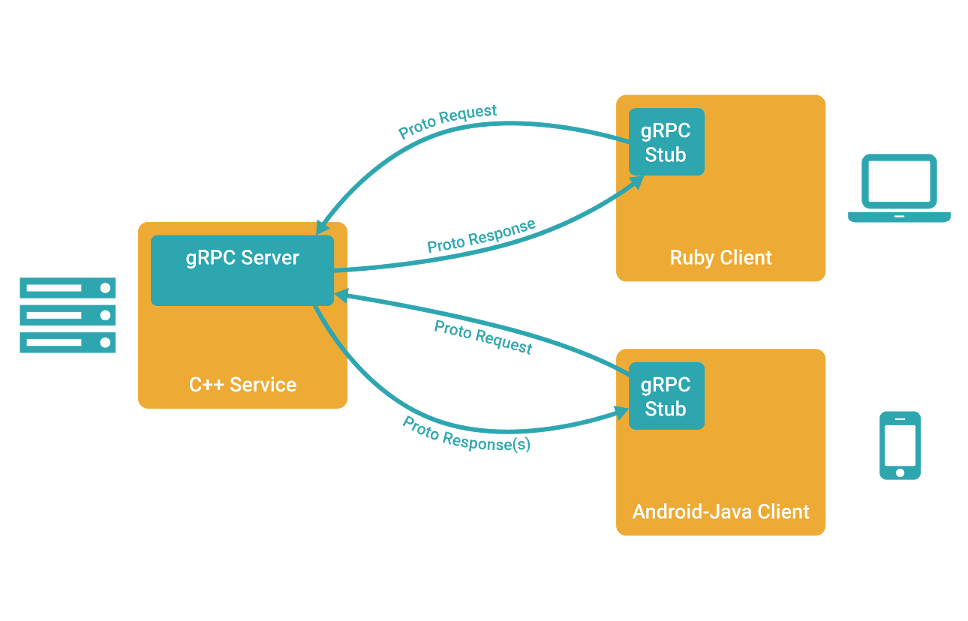
gRPC 允许你定义四类服务方法:
-
单项 RPC,即客户端发送一个请求给服务端,从服务端获取一个应答,就像一次普通的函数调用。
-
服务端流式 RPC,即客户端发送一个请求给服务端,可获取一个数据流用来读取一系列消息。客户端从返回的数据流里一直读取直到没有更多消息为止。
-
客户端流式 RPC,即客户端用提供的一个数据流写入并发送一系列消息给服务端。一旦客户端完成消息写入,就等待服务端读取这些消息并返回应答。
-
双向流式 RPC,即两边都可以分别通过一个读写数据流来发送一系列消息。这两个数据流操作是相互独立的,所以客户端和服务端能按其希望的任意顺序读写,例如:服务端可以在写应答前等待所有的客户端消息,或者它可以先读一个消息再写一个消息,或者是读写相结合的其他方式。每个数据流里消息的顺序会被保持。
1、Protocol Buffers
Google Protocol Buffer( 简称 Protobuf) ,Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
Protobuf实际是一套类似Json或者XML的数据传输格式和规范,用于不同应用或进程之间进行通信时使用。通信时所传递的信息是通过Protobuf定义的message数据结构进行打包,然后编译成二进制的码流再进行传输或者存储。
相比较而言,Protobuf有如下优点:
- 序列化后体积很小:消息大小只需要XML的1/10 ~ 1/3
- 解析速度快:解析速度比XML快20 ~ 100倍
- 多语言支持
- 更好的兼容性,Protobuf设计的一个原则就是要能够很好的支持向下或向上兼容
2、Protocol Buffers特点
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
- 序列化数据时,不序列化key的name,使用key的编号替代,减小数据。如上面的数据在序列化时query ,page_number以及result_per_page的key不会参与,由编号1,2,3替代,这样在反序列的时候可以直接通过编号找到对应的key,这样做确实可以减小传输数据,但是编号一旦确定就不可更改;
- 版本直接兼容:字段操作可以在无需重新部署程序的情况下更新数据结构
- 必须不可以改变已经存在的标签的数字
- 必须不可以增加或删除必须(required)字段。
- 可以删除可选(optional)或重复(repeated)字段。
- 可以添加新的可选或重复字段,但是必须使用新的标签数字,必须是之前的字段所没有用过的。
- 没有赋值的key,不参与序列化:序列化时只会对赋值的key进行序列化,没有赋值的不参与,在反序列化的时候直接给默认值即可;
- 可变长度编码:主要缩减整数占用字节实现,例如java中int占用4个字节,但是大多数情况下,我们使用的数字都比较小,使用1个字节就够了,这就是可变长度编码完成的事;
- TLV: TLV全称为Tag_Length_Value,其中Tag表示后面数据的类型,Length不一定有,根据Tag的值确定,Value就是数据了,TLV表示数据时,减少分隔符的使用,更加紧凑;
3、数据结构
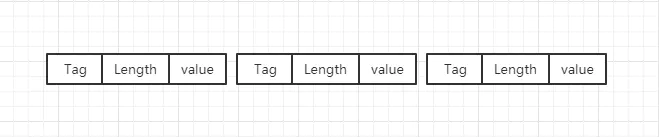
Tag块并不是只表示数据类型,其中数据编号也在Tag块中,Tag的生成规则如下:Tag块的后3位表示数据类型,其他位表示数据编号。Tag中1-15编号只占用1个字节,所以确保编号中1-15为常用的,减少数据大小。
其中Length不一定有,依据Tag确定,例如数值类型的数据,使用VarInts不需要长度,就只有Tag-Value,string类型的数据就必须是Tag-Length-Value
4、数据类型
| 类型 | 释义 | 备注 |
|---|---|---|
| 0 | 可变长度编码 | int32 int64 uint32 uint64 sint32 sint64 bool enum |
| 1 | 64位固定长度 | fixed64 sfixed64 double |
| 2 | value 的长度 | string bytes message packed repeated fiels |
| 3 | Start Group | 已废弃 |
| 4 | End Group | 已废弃 |
| 5 | 32位长度 | fixed32 sfixed32 float |
(field_number << 3) | wire_type
低三位表示wire type,其他的位表示field number(编号)。
5、VARInts/Zigzag
int值一般都是固定的4字节,可表示的整数范围为-2^31——2^31-1,但是实际开发中用到的数字均比较小,会造成字节浪费。
Varints是protobuf的序列化整型数据的一种编码方式,它的优点是整型数据的值越小,编码后所用的字节数越小。
经过Varints编码后的数据,它的每一个字节8bit的高位代表一个标记位。
- 如果标记位是1,则代表下一个字节仍然是当前整型数据的组成;
- 如果标记位是0,则代表下一个字节就是下一个整型数据了。
先看最简单的数值1,一个字节足以表示它,所以它的标记位置0:
0000 0001
再看数值300,经过Varints编码后的序列:
1010 1100 0000 0010
换算的时候,从左到右,依次将每个字节的高位(标志位)去掉,Protocol Buffer是低位在前,转换后拼接
1010 1100 0000 0010
(去除标志位)
→ 010 1100 000 0010
(转换拼接)
→ 000 0010 010 1100
(进制)
→ 300
可变长度编码唯一的缺点就是当数很大的时候int32需要占用5个字节,但是从统计学角度来说,一般不会有这么大的数。
对于负数的处理方式是不同的。如果用int32或者int64来编码一个负数的话,通常需要耗费10个字节来表示,因为负数在计算机中是以补码表示的,相当于一个数值很大的无符号数。
所以这个时候就需要用「有符号」的整型(sint32,sint64)来表示负数了,它们先使用ZigZag编码方式将负数转换为绝对值较小正数,再进行Varints编码。
6、编码
message Test1{
required int32 id = 1;
}
如果我们将number赋值为300,则Message进行编码序列化以后以16进制输出为
08 96 01
其中第一个字节08
0000 1000
wire type为0,field name为1。符合id的类型是int32,编码方式是Varints,field是1的这一情况。
12c 02则分别为1010 1100和0000 0010的16进制
message Test2
{
required string str = 2;
}
如果将str赋值为’testing’,然后把经过protobuf编码序列化后的数据以16进制的方式输出
12 07 74 65 73 74 69 6e 67
第一个字节0x12表示field name为2,wire type为2。第二个字节0x07表示数据长度为7,所以后面7个字节就是使用UTF8编码的testing。
7、总结
- Protocol Buffer 利用 varint 原理压缩数据以后,二进制数据非常紧凑,option 也算是压缩体积的一个举措。所以 pb 体积更小,如果选用它作为网络数据传输,势必相同数据,消耗的网络流量更少。但是并没有压缩到极限,float、double 浮点型都没有压缩。
- Protocol Buffer 比 JSON 和 XML 少了 {、}、: 这些符号,体积也减少一些。再加上 varint 压缩,gzip 压缩以后体积更小!
- Protocol Buffer 是 Tag - Value (Tag - Length - Value)的编码方式的实现,减少了分隔符的使用,数据存储更加紧凑。
- Protocol Buffer 另外一个核心价值在于提供了一套工具,一个编译工具,自动化生成 get/set 代码。简化了多语言交互的复杂度,使得编码解码工作有了生产力。
- Protocol Buffer 不是自我描述的,离开了数据描述 .proto 文件,就无法理解二进制数据流。这点即是优点,使数据具有一定的“加密性”,也是缺点,数据可读性极差。所以 Protocol Buffer 非常适合内部服务之间 RPC 调用和传递数据。
- Protocol Buffer 具有向后兼容的特性,更新数据结构以后,老版本依旧可以兼容,这也是 Protocol Buffer 诞生之初被寄予解决的问题。因为编译器对不识别的新增字段会跳过不处理。