0、统计方案
应用启动耗时统计除了有通过代码来计算,还有一种方案就是通过录屏,然后查看视频,一帧一帧的人工识别启动帧和加载完成的帧,并且用时间戳相减,从而得到启动耗时时间。


这种方案如果多次人工识别就很繁琐,所以我们引入机器学习
1、机器学习自动识别过程
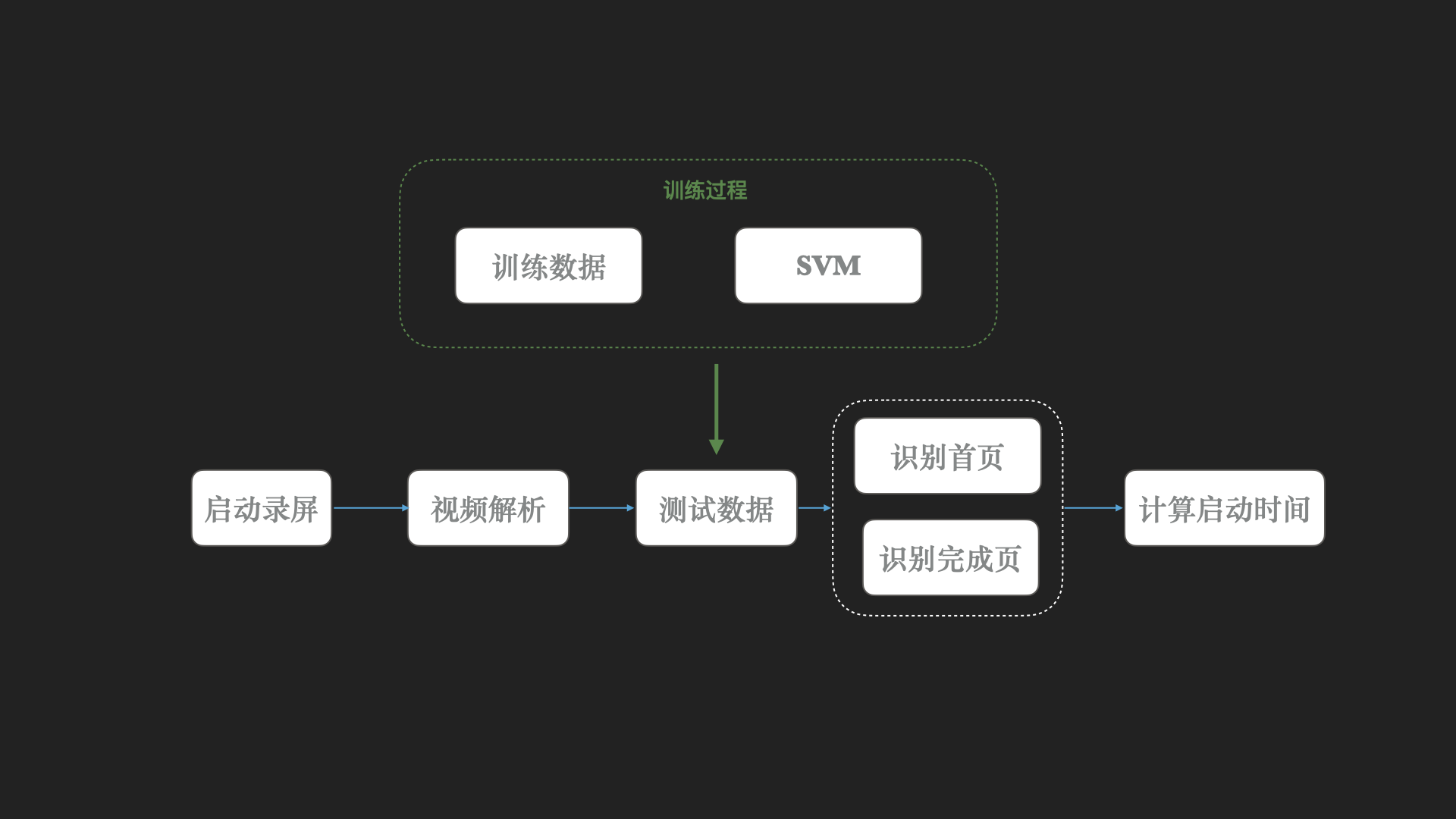
这是一个典型的图像识别,因此选择了SVM模型训练数据,通过有监督学习,建立图像和labal之间的对应关系。
框架选择方面,这是传统的机器学习,所以用的是Scikit-learn框架
2、准备训练数据
iOS的启动过程:
- 启动前
- 点击启动iCon
- 默认LaunchScreen
- 广告页
- 首页出现
- 首页加载完毕
def cut_video(i_video,o_video):
print 'cuting...'
videoCap= cv2.VideoCapture(i_video)
if not videoCap.isOpened():
log = i_video + " 该输入路径视频不存在,请检查"
print(log)
success, frame = videoCap.read()
count = 0
while success:
if cv2.waitKey(1) == 27:
break
count += 1
success, frame = videoCap.read()
cv2.imwrite(os.path.join(o_video, 'o_' + str(count) + '.jpg'), frame)
videoCap.release()
将训练视频按帧分割,这里用的是cv2的库
def make_dir(folder):
feature_dir = os.path.join(os.getcwd(), folder)
if not os.path.exists(feature_dir):
os.makedirs(feature_dir)
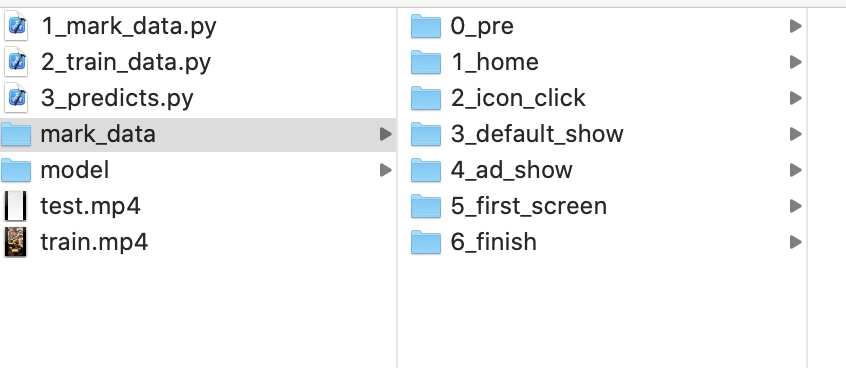
def make_all_folder():
make_dir('mark_data/0_pre') # 桌面前
make_dir('mark_data/1_home') # 桌面状态
make_dir('mark_data/2_icon_click') # 点击icon
make_dir('mark_data/3_default_show') # 默认启动图
make_dir('mark_data/4_ad_show') # 广告页
make_dir('mark_data/5_first_screen') # 首页
make_dir('mark_data/6_finish') # 完成
生成几个阶段的文件夹,然后将分割好的图片放入对应的阶段
3、模型训练
减少数据大小,将图片缩小10倍,导入标签
def pre_train_datas():
global img_w
global img_h
label_list = []
image_list = []
image_classes = os.listdir("mark_data")
for classes in image_classes:
image_dir = os.getcwd() + '/mark_data/' + classes
if not os.path.isdir(image_dir):
continue
for image_path in os.listdir(image_dir)[:-1]:
if image_path.endswith(".jpg"):
img = Image.open(image_dir+"/"+image_path)
img_w, img_h = img.size
img.thumbnail((img_w//10, img_h//10))
image_list.append(np.asarray(img).flatten())
label_list.append(classes)
return image_list, label_list
用SVM训练,得到model
def training_model():
train_img, train_label = pre_train_datas()
linear_svc = svm.LinearSVC()
linear_svc.fit(train_img, train_label)
model_name = 'model/' + str(img_w) + '_' + str (img_h) + '_model'
joblib.dump(linear_svc, model_name)
4、测试
将测试视频输入后按帧分割,进行识别,记录启动时和加载完成的时间戳,将时间戳一减便能得到启动时间
def check_video(i_video):
videoCap= cv2.VideoCapture(i_video)
if not videoCap.isOpened():
log = i_video + " 该输入路径视频不存在,请检查"
print(log)
width = int(videoCap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(videoCap.get(cv2.CAP_PROP_FRAME_HEIGHT))
model_name = 'model/' + str(width) + '_' + str(height) + '_model'
clf = joblib.load(model_name)
success = True
start = 0.0
end = 0.0
count = 0
while success:
success, frame = videoCap.read()
count += 1
if success:
milliseconds = videoCap.get(cv2.CAP_PROP_POS_MSEC)
img = Image.fromarray(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB))
img.thumbnail((width//10, height//10))
a = np.array(img).reshape(1, -1)
predicts = clf.predict(a)
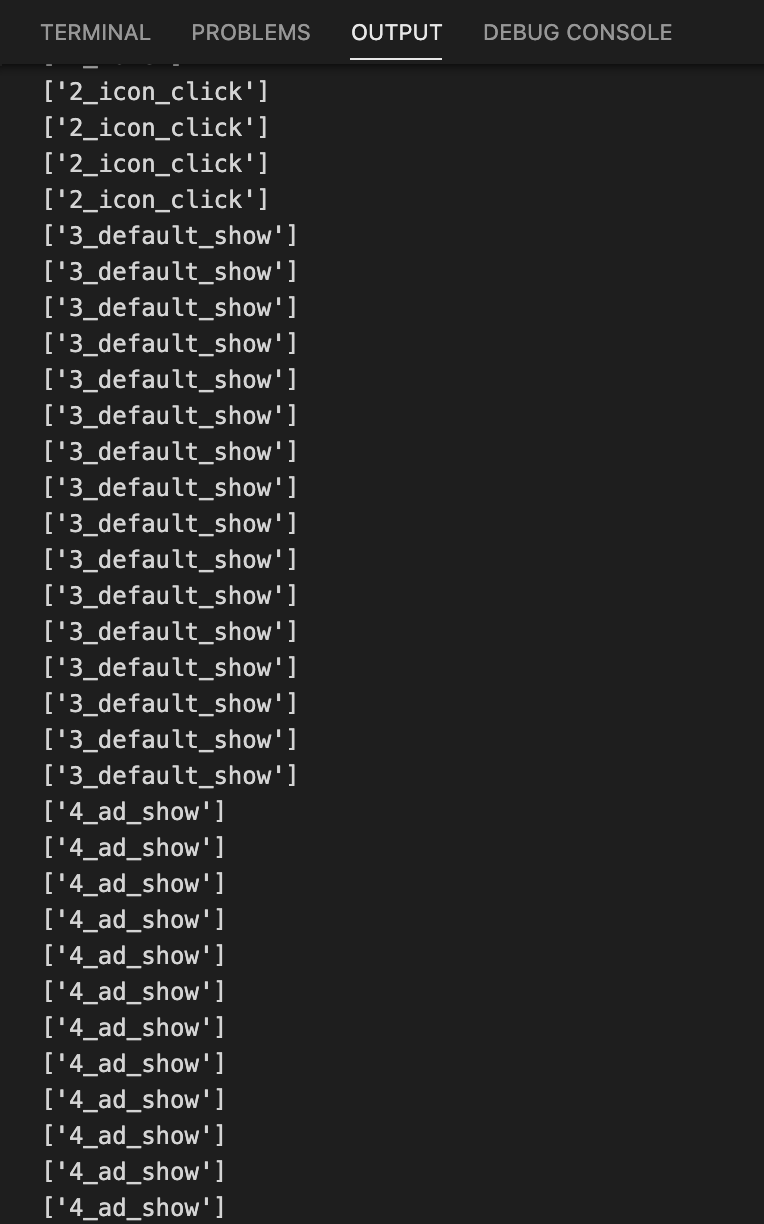
print predicts
if predicts[0] == '2_icon_click' and start == 0:
start = milliseconds
if predicts[0] == '6_finish' and end == 0:
end = milliseconds
duration = end - start
print '本次启动时间:' + str(int(duration)) + 'ms'