一、业务背景
1.1. 秒杀说明
在当今的电商环境中,直播带货已成为一种重要的销售渠道,吸引了大量用户参与。为了提升用户的购买体验和参与感,超核直播间引入了“优惠券秒杀”功能。这一功能不仅能够激发用户的购买欲望,还能有效提升直播间的互动性和活跃度。
优惠券秒杀功能允许主播在直播过程中通过口播的方式实时上架优惠券。用户在观看直播时,可以通过抢券的方式获取大额优惠券,从而提高购买转化率。该功能的设计旨在增强用户的参与感和紧迫感,提升直播间的整体活跃度。
这些优惠券通常是游戏道具的大额满减,对于观看直播的玩家具有很大吸引力,所以秒杀活动参与热情很高。
1.2 参与角色
- 主播:在直播过程中,主播负责通过口播的方式介绍并上架优惠券。主播的表现和互动能力直接影响用户的参与度和购买意愿。
- 运营团队:运营团队在后台系统中负责录入和发布优惠券信息,包括优惠券的类型、数量、有效期等。运营团队需要确保信息的准确性和及时性,以便用户能够顺利参与抢券活动。
- 用户:用户在观看直播时,会看到前端页面显示的倒计时弹窗,提示“30秒后开始抢券”。用户需要在倒计时结束后,点击抢券按钮参与活动。
- 技术团队:通过综合考虑高并发处理、数据一致性、用户体验和安全性等多个方面,设计一个高效、稳定、安全的优惠券秒杀抢购方案,确保秒杀活动的顺利进行和用户的良好体验。
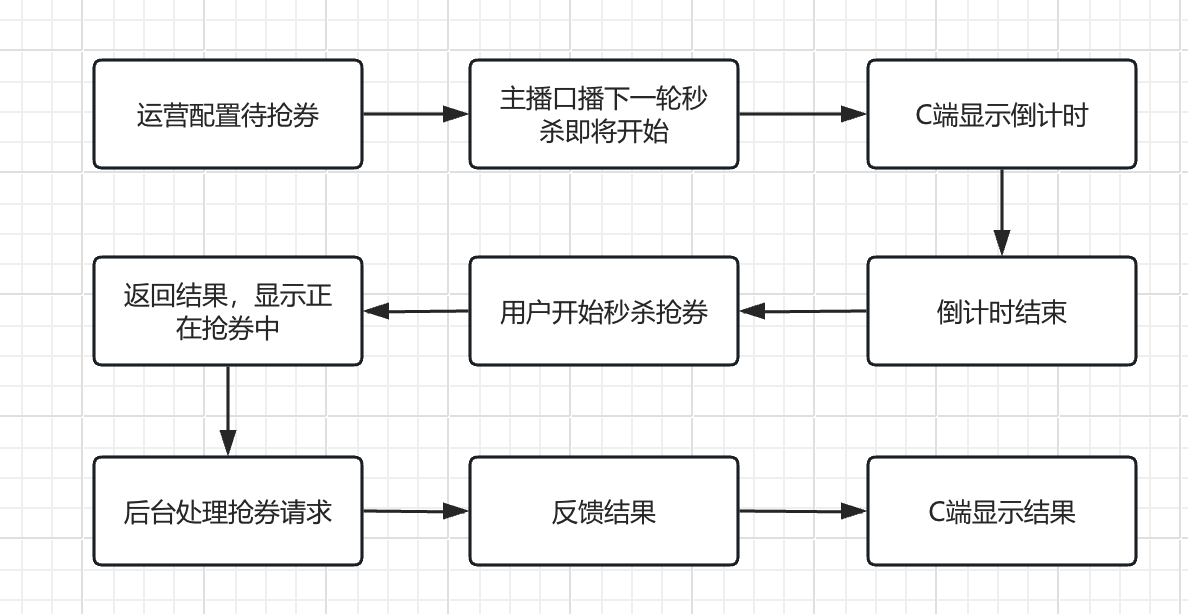
1.3 业务流程
- 优惠券录入:
- 提前录入:运营团队在直播开始前在后台系统中录入相关的优惠券信息,确保优惠券的发放和使用规则准确无误。
- 优惠券上架:
- 主播口播:在直播过程中,主播通过口播的方式告知观众即将上架的优惠券信息,包括优惠券的类型、数量、使用条件等。
-
运营推送:运营团队在后台系统中发布提前录入的相关的优惠券信息,并推送zhi。
-
倒计时提示:
-
前端页面显示倒计时弹窗:在优惠券上架的同时,前端页面会显示一个倒计时弹窗,提示用户“30秒后开始抢券”,并开始倒计时。
-
倒计时逻辑:倒计时逻辑由前端实现,确保倒计时的准确性和用户体验。
-
-
抢券开始:
-
倒计时结束:当倒计时结束后,抢券按钮将变为可点击状态,用户可以点击该按钮开始抢券。
-
用户点击抢券:用户点击抢券按钮后,前端将请求发送到后端服务器,进行抢券操作。
-
- 抢券处理:
- 后端处理请求:后端服务器接收到用户的抢券请求后,进行相应的处理,包括验证用户资格、检查优惠券库存、生成优惠券等。
-
反馈结果:后端处理完成后,将结果反馈给前端,前端根据结果显示相应的提示信息,如“抢券成功”或“优惠券已抢完”。
二、技术方案
高并发处理:秒杀活动通常会有大量用户同时访问,导致服务器压力剧增,需要设计高效的并发处理方案。
有以下的技术挑战:
- 用户体验:秒杀活动需要快速响应用户请求,提供良好的用户体验,避免长时间的等待和页面卡顿。
- 高并发处理:秒杀活动通常会有大量用户同时访问,导致服务器压力剧增,需要设计高效的并发处理方案。
- 安全性:秒杀活动容易受到恶意攻击,如刷单、爬虫等,需要设计有效的安全防护措施。
- 公平性:秒杀活动是在倒计时结束后统一启动,所以需要保证好前端时间同步,用户能在同一时间开始秒杀。
- 数据一致性:在高并发场景下,保证优惠券库存和用户抢券结果的一致性是一个挑战。
2.1 用户体验
目标:提供快速响应的用户体验,避免长时间的等待和页面卡顿。
快速反馈:
- 异步处理:将抢券请求异步处理,快速返回请求已接收的反馈,减少用户等待时间。
- 前端提示:在前端页面显示请求处理中提示,提升用户体验。
页面优化:
- 静态资源优化:优化前端静态资源的加载速度,减少页面加载时间。
- CDN加速:使用CDN加速前端资源的分发,提升页面响应速度。
降级策略:
- 功能降级:在系统压力过大时,适当关闭部分非核心功能,保证核心秒杀功能的稳定性。
- 限流降级:在高并发场景下,适当降低限流阈值,保证系统稳定运行。
2.2 高并发处理
目标:在秒杀活动中处理大量并发请求,确保系统稳定性和响应速度。
前端限流:
- 限流策略:在前端对用户请求进行限流,限制每个用户在一定时间内的请求次数。
- 倒计时提示:在秒杀开始前,通过倒计时提示用户,减少无效请求。
后端限流:
- 限流:在北极星引使用限流算法,在对请求进行限流,防止瞬时高并发请求压垮服务器。
消息队列:
- 异步处理:将用户的抢券请求通过消息队列异步处理,削峰填谷,缓解瞬时高并发压力。
缓存:
- 缓存热点数据:将优惠券库存等热点数据缓存到Redis等高性能缓存中,减少数据库访问压力。
2.3 安全性
目标:防止恶意攻击,如刷单、爬虫等,保障系统安全。
用户权限限制:
- 资格认证:只有超核用户才能够参与秒杀抢券
验证码:
- 图形验证码:在用户抢券前,要求用户输入图形验证码,防止恶意刷单。
- 行为验证码:使用滑动验证等行为验证码,提升安全性。
IP限流:
- IP黑名单:对恶意IP进行黑名单处理,禁止其访问系统。
- IP限流策略:对单个IP的请求频率进行限制,防止恶意攻击。
2.4 公平性
目标:保证秒杀活动在倒计时结束后统一启动,确保所有用户在同一时间开始秒杀,提升活动的公平性
- 时间同步:
- NTP时间同步:在服务器端使用NTP(网络时间协议)进行时间同步,确保所有服务器的时间一致。
- 前端时间校准:在前端页面加载时,通过与服务器进行时间校准,确保前端显示的倒计时与服务器时间一致。
2.5 数据一致性
目标:保证在尽量提升性能的情况下,保证券不出现超卖现象
三、高并发防止超卖
高并发抢券,可能会出现超卖问题,针对超卖问题,业界有以下几种解决方案:
3.1. 数据库悲观锁
在进行库存查询和更新时,使用数据库的悲观锁机制(如 SELECT … FOR UPDATE)来锁定库存记录,确保在同一时间只有一个请求可以修改库存。
优势
- 通过锁机制,确保在并发情况下库存数据的一致性。
- 在现有的数据库架构中,直接使用锁机制即可实现。
劣势
- 在高并发情况下,锁会导致请求排队,影响系统性能。
- 如果不当使用,可能会导致死锁,影响系统稳定性。
可能出现的问题
- 在高并发情况下,锁竞争严重,可能导致用户体验下降。
- 需要合理设置锁的超时时间,以避免长时间锁定导致的性能问题。
3.2. 数据库乐观锁
在库存更新时,使用乐观锁机制(如版本号或时间戳)来判断库存是否被其他请求修改。只有在版本号匹配的情况下才进行更新。
优势
- 高并发性能:乐观锁在没有冲突时性能较好,适合读多写少的场景。
- 避免锁竞争:减少了锁的使用,降低了死锁的风险。
劣势
- 冲突重试:在高并发情况下,可能会频繁出现更新失败的情况,需要重试,增加了复杂性。
- 数据库压力较大,容易成为瓶颈。
可能出现的问题
- 在高并发情况下,频繁的重试可能导致性能下降。
- 需要合理设计重试机制,以避免无限重试导致的资源浪费。
3.3. Redis 分布式锁
使用 Redis 的分布式锁机制(如 Redisson 或 Lua 脚本)来控制对库存的访问。通过设置锁的过期时间,确保在高并发情况下的安全性。
优势
- 高性能:Redis 的性能优于传统数据库,能够处理高并发请求。
- 灵活性:可以设置锁的过期时间,避免长时间锁定。
劣势
- 流程需要引入 Redis,增加了系统的复杂性。
- 锁失效风险:如果在持有锁的过程中发生故障,可能导致锁失效,影响系统稳定性。
可能出现的问题
- 需要处理锁的过期和续期逻辑,以避免锁失效导致的超卖。
- Redis 的单点故障问题需要考虑,建议使用 Redis 集群。
3.4. Redis库存预减
在秒杀开始前,将库存数据预加载到Redis中。用户请求到达时,先在Redis中预减库存,成功后再进行后续操作。
优势:
- 高性能,Redis操作速度快,适合高并发场景。
- 减少数据库压力,提升系统整体性能。
劣势:
- 需要处理Redis和数据库的一致性问题,增加实现复杂度。
- Redis数据丢失可能导致库存不一致。
可能出现的问题:
- Redis和数据库数据不一致,导致超卖或库存浪费。
- Redis数据丢失导致库存数据不准确。
3.5. 队列限流
在秒杀活动开始时,使用消息队列来控制请求的流量。用户请求先进入队列,后端系统按顺序处理请求。
优势
- 流量控制:有效控制并发请求的数量,避免瞬时流量冲击数据库。
- 解耦:将请求处理与库存更新解耦,提高系统的可扩展性。
劣势
- 需要引入消息队列,增加了系统的复杂性。
- 由于请求需要排队处理,可能导致性能下降。
可能出现的问题
- 需要合理设计队列的消费速率,以避免队列积压。
- 消息丢失或重复消费的风险需要处理。
3.6、综合对比
| 方案 | 优势 | 劣势 | 可能出现的问题 |
|---|---|---|---|
| 数据库乐观锁 | 实现简单,维护成本低 | 重试次数多,数据库压力大 | 性能下降,锁竞争激烈 |
| 数据库悲观锁 | 数据一致性强,避免超卖 | 锁竞争激烈,性能瓶颈 | 锁等待时间长,数据库性能下降 |
| Redis分布式锁 | 高性能,适合高并发场景 | 实现复杂度高,Redis单点故障 | 锁超时导致数据不一致,Redis故障导致锁失效 |
| Redis库存预减 | 高性能,减少数据库压力 | 实现复杂度高,需要处理一致性问题 | Redis和数据库数据不一致,Redis数据丢失 |
| 消息队列异步处理 | 削峰填谷,保证请求按顺序处理 | 实现复杂度高,用户等待时间长 | 消息队列故障导致请求丢失或处理延迟 |
四、超核抢券秒杀的方案
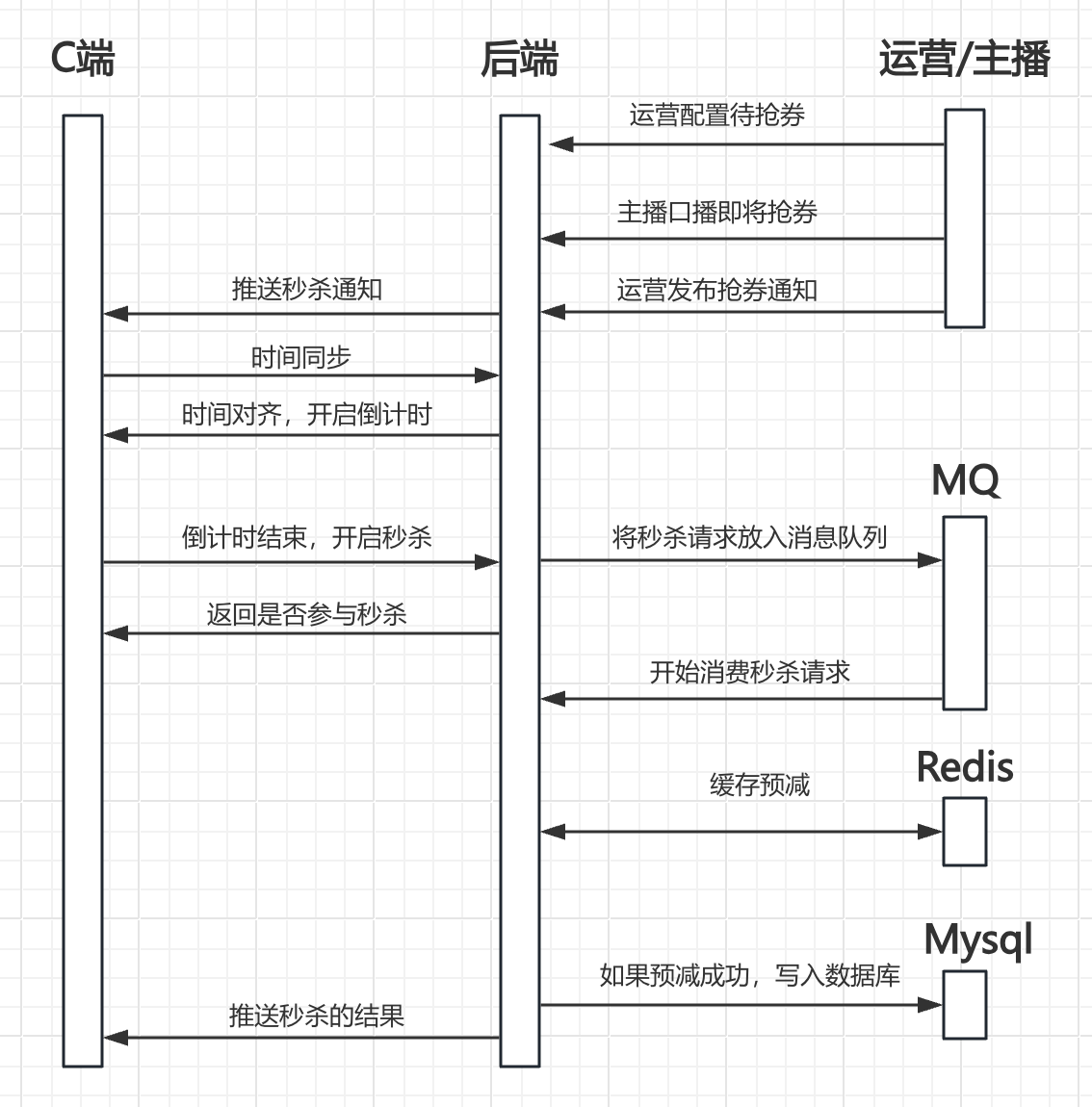
4.1 超核秒杀流程
综合几个防止超卖的方案,结合超核的实际情况,超核的最终抢券秒杀方案的流程如下:
- 运营提前配置待抢购的券
- 主播口播即将开始下一轮抢券
- 运营将下一轮抢券通知推送到C端,服务端将改券信息做缓存预热。
- C端接受下一轮通知,进行时间同步
- C端开始倒计时
- C端倒计时结束,用户开始抢券,发送抢券请求
- 服务端接受用户抢券请求,并验证用户是否有资格参与,如果是,则将抢券请求放入消息队列。
- C端接受服务端返回用户是否参与抢券,并显示”抢券中”。
- 服务端消费抢券请求,通过Redis+lua进行单线程库存预减。
- 处理预减结果:
- 预减成功,写入数据库,告知前端用户抢券成功
- 预减失败,推送告知前端用户抢券失败
-
复盘统计本次抢券结果。
4.2、技术挑战如何解决的
用户体验:
- 解决方案:在用户发起秒杀请求时,首先在Redis中进行资格验证(如是否为超核用户、同一IP是否已参与等),验证通过后立即返回结果,并将请求写入消息队列进行后续处理。
- 效果:用户在秒杀请求时,只需进行资格验证即可立即返回结果,不会有长时间的等待。
高并发处理:
- 解决方案:使用消息队列来缓冲高并发请求,后端系统按顺序从队列中读取请求并处理,避免瞬时高并发对系统的冲击。
- 效果:削峰控制并发流量。
安全性:
- 解决方案:在Redis中存储用户资格信息和IP参与记录,确保每个用户和IP只能参与一次。
- 效果:避免非超核用户参与可以保证安全性。同一个IP只能参与一次。
公平性
- 解决方案:使用NTP(网络时间协议)进行时间同步,确保前后端时间一致。
- 效果:前后端时间同步,保证同一时间开启秒杀。
数据一致性:
- 解决方案:使用Redis和Lua脚本进行库存预减操作,Lua脚本在Redis中是原子执行的,确保库存检查和预减操作在一个原子操作中完成,避免并发问题导致的超卖。
- 效果:在处理库存更新时,Redis+Lua的预减方案,原子操作不会出现超卖。
性能:
- 解决方案:利用Redis的高性能和Lua脚本的原子性,快速处理高并发请求。同时,通过消息队列缓冲请求,进一步提高系统的处理能力。
- 效果:高效处理高并发请求。
高可用
- 解决方案:使用Redis集群,避免单点故障
- 效果:避免单点故障
五、业界秒杀方案补充
针对秒杀活动场景,业界还有一些提高性能和稳定性的方案:
5.1 热点隔离
秒杀系统设计的第一个原则就是将这种热点数据隔离出来,不要让1%的请求影响到另外的99%,隔离出来后也更方便对这1%的请求做针对性优化。针对秒杀我们做了多个层次的隔离:
- 业务隔离:因为秒杀业务高并发高流量的特殊性,将其从系统中隔离出来,防止影响其他业务。
- 系统隔离。系统隔离更多是运行时的隔离,可以通过分组部署的方式和另外99%分开。甚至可以单独的域名,目的也是让请求落到不同的集群中。
- 数据隔离。秒杀所调用的数据大部分都是热数据,这部分数据库可以做隔离。
实现隔离很有多办法,如可以按照用户来区分,给不同用户分配不同cookie,在接入层路由到不同服务接口中;还有在接入层可以对URL的不同Path来设置限流策略等。服务层通过调用不同的服务接口;数据层可以给数据打上特殊的标来区分。目的都是把已经识别出来的热点和普通请求区分开来。
5.2 动静分离
在秒杀页面用户可能会不断刷鞋页面:通过以下措施将静态数据与动态数据隔离:
- 把整个页面Cache在用户浏览器
- 如果强制刷新整个页面,也会请求到CDN
- 实际有效请求只是“刷新抢券”按钮
这样把90%的静态数据缓存在用户端或者CDN上,当真正秒杀时用户只需要点击特殊的按钮“刷新抢券”即可,而不需要刷新整个页面,这样只向服务端请求很少的有效数据,而不需要重复请求大量静态数据。秒杀的动态数据和普通的详情页面的动态数据相比更少,性能也比普通的详情提升3倍以上。
5.3 基于时间分片削峰
倒计时结束,用户开始秒杀,可以在此阶段对用户分流,比如增加人机验证,答题验证,从而达到基于时间分片在前端就进行了削峰
5.4 数据分层校验
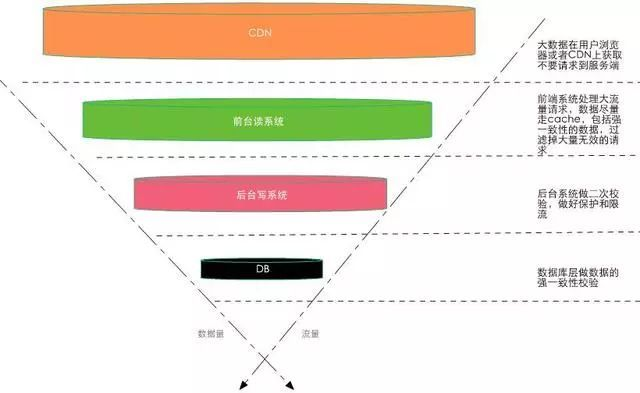
对大流量系统的数据做分层校验也是最重要的设计原则,所谓分层校验就是对大量的请求做成“漏斗”式设计,如所示:在不同层次尽可能把无效的请求过滤,“漏斗”的最末端才是有效的请求,要达到这个效果必须对数据做分层的校验,下面是一些原则:
- 先做数据的动静分离
- 将90%的数据缓存在客户端浏览器
- 将动态请求的读数据Cache在Web端
- 对读数据不做强一致性校验
- 对写数据进行基于时间的合理分片
- 对写请求做限流保护
- 对写数据进行强一致性校验