一、MySQL架构
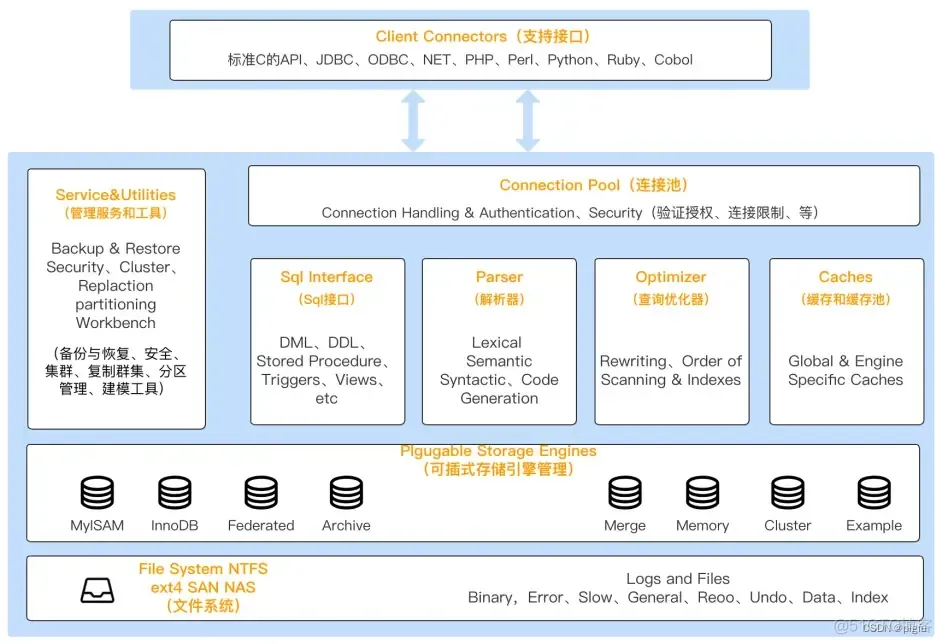
MySQL 的架构共分为两层:Server 层、存储引擎层:
- Server 层负责建立连接、分析和执行 SQL。MySQL 大多数的核心功能模块都在这实现,主要包括连接器,查询缓存、解析器、预处理器、优化器、执行器等。另外,所有的内置函数(如日期、时间、数学和加密函数等)和所有跨存储引擎的功能(如存储过程、触发器、视图等。)都在 Server 层实现。
- 存储引擎层负责数据的存储和提取。支持 InnoDB、MyISAM、Memory 等多个存储引擎,不同的存储引擎共用一个 Server 层。现在最常用的存储引擎是 InnoDB,从 MySQL 5.5 版本开始, InnoDB 成为了 MySQL 的默认存储引擎。我们常说的索引数据结构,就是由存储引擎层实现的,不同的存储引擎支持的索引类型也不相同,比如 InnoDB 支持索引类型是 B+树 ,且是默认使用,也就是说在数据表中创建的主键索引和二级索引默认使用的是 B+ 树索引。
执行一条 SQL 查询语句,期间发生了什么?
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。
- 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
1、连接器
MySQL 是基于 TCP 协议进行传输的。
连接器的工作:
- 与客户端进行 TCP 三次握手建立连接;
- 校验客户端的用户名和密码,如果用户名或密码不对,则会报错;
- 如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限;
如何查看 MySQL 服务被多少个客户端连接了?
可以执行 show processlist 命令进行查看。
空闲连接会一直占用着吗?
MySQL 定义了空闲连接的最大空闲时长,由 wait_timeout 参数控制的,默认值是 8 小时(28880秒),如果空闲连接超过了这个时间,连接器就会自动将它断开。
手动断开空闲的连接,使用的是 kill connection + id 的命令。
MySQL 的连接数有限制吗?
MySQL 服务支持的最大连接数由 max_connections 参数控制,比如我的 MySQL 服务默认是 151 个,超过这个值,系统就会拒绝接下来的连接请求,并报错提示“Too many connections”。
长连接和短连接、连接池
短连接就是我们开发的应用程序需要访问数据库时候,需要建立数据连接,执行SQL操作,关闭连接。简单讲就是每一次操作数据库,都要执行一次上述操作。它的弊端就是:如果网络速度不是很理想的情况下,短连接的会消耗大量的系统资源,在生产环境中,业务很多的话,可能 1 秒内几千个连接,如果都是短连接,且 sql 处理慢的话,连接关闭不及时,那么资源耗尽速度可能发生在几分钟甚至几秒,所以我们系统不大可能一直是短连接。
长连接是指我们的程序和数据库连接之后,就一直打开,后面程序来访问相同数据库就复用该连接,使用长连接主要是考虑到减少短连接连接的开销,但是从服务器端来看,维持一个连接会占用服务器内存,如果所有程序都是长连接,肯定会有部分连接处于闲置状态,但是无论什么状态连接,都占用内存,这会造成服务器端的资源浪费,也显得不是很高效。
连接池,它是一个预先创建的连接缓冲池,考虑到某些数据进行连接之后,处理时间过长,而不想它闲置,允许给其他线程使用。一般现在的应用服务器都带有连接池组件,允许应用程序,客户端来连接,应用服务器维护着连接池的整个生命周期。数据库连接池技术的思想非常简单,将数据库连接作为对象存储在一个Vector对象中,一旦数据库连接建立后,不同的数据库访问请求就可以共享这些连接,这样,通过复用这些已经建立的数据库连接,可以克服无论长连接和短连接缺点,极大地节省系统资源和时间
怎么解决长连接占用内存的问题?
- 定期断开长连接。既然断开连接后就会释放连接占用的内存资源,那么我们可以定期断开长连接。
- 客户端主动重置连接。
- 连接池
2、查询缓存
MySQL 8.0 版本之后没有查询缓存这一步了。
连接器得工作完成后,客户端就可以向 MySQL 服务发送 SQL 语句了,MySQL 服务收到 SQL 语句后,就会解析出 SQL 语句的第一个字段,看看是什么类型的语句。
如果 SQL 是查询语句(select 语句),MySQL 就会先去查询缓存( Query Cache )里查找缓存数据,看看之前有没有执行过这一条命令,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。如果查询的语句命中查询缓存,那么就会直接返回 value 给客户端。如果查询的语句没有命中查询缓存中,那么就要往下继续执行,等执行完后,查询的结果就会被存入查询缓存中。
真实情况是查询缓存挺鸡肋的。对于更新比较频繁的表,查询缓存的命中率很低的,因为只要一个表有更新操作,那么这个表的查询缓存就会被清空。如果刚缓存了一个查询结果很大的数据,还没被使用的时候,刚好这个表有更新操作,查询缓冲就被清空了,相当于缓存了个寂寞。
所以,MySQL 8.0 版本直接将查询缓存删掉了,也就是说 MySQL 8.0 开始,执行一条 SQL 查询语句,不会再走到查询缓存这个阶段了。这里说的查询缓存是 server 层的,也就是 MySQL 8.0 版本移除的是 server 层的查询缓存,并不是 Innodb 存储引擎中的 buffer pool。
3、解析 SQL
在正式执行 SQL 查询语句之前, MySQL 会先对 SQL 语句做解析,这个工作交由「解析器」来完成。
解析器会做如下两件事情。
- 词法分析。MySQL 会根据你输入的字符串识别出关键字出来
- 语法分析。根据词法分析的结果,语法解析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法,如果没问题就会构建出 SQL 语法树,这样方便后面模块获取 SQL 类型、表名、字段名、 where 条件等等
4、执行 SQL
经过解析器后,接着就要进入执行 SQL 查询语句的流程了,每条SELECT 查询语句流程主要可以分为下面这三个阶段:
-
prepare 阶段,也就是预处理阶段;
-
检查 SQL 查询语句中的表或者字段是否存在;
-
将 select * 中的 * 符号,扩展为表上的所有列;
-
- optimize 阶段,也就是优化阶段:优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
- execute 阶段,也就是执行阶段:真正开始执行语句了,这个工作是由「执行器」完成的。在执行的过程中,执行器就会和存储引擎交互了,交互是以记录为单位的。
二、InnoDB架构
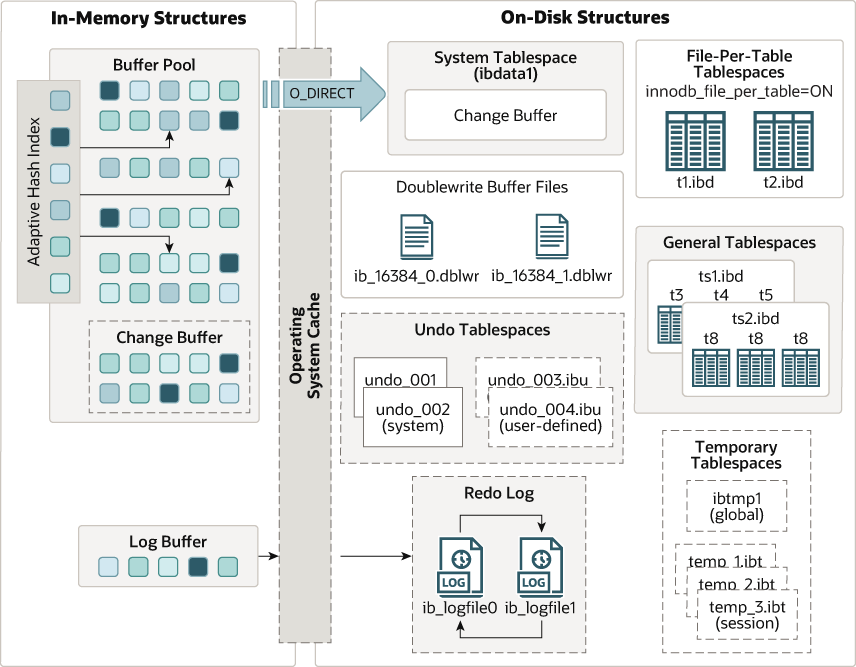
InnoDB整体也分为三层:
- 内存结构(In-Memory Structure),这一层在MySQL服务进程内;
- OS Cache,这一层属于内核态内存;
- 磁盘结构(On-Disk Structure),这一层在文件系统上;
这三层的交互有两类:
- 直接O_Direct落地数据(长途中,长箭头):Buffer Pool的数据与磁盘数据;
- 通过OS Cache落地数据(上图中,两个短箭头):Log Buffer;
内存区域
InnoDB内存结构包含四大核心组件,分别是:
- 缓冲池(Buffer Pool):加速读请求,避免每次数据访问都进行磁盘IO,起到Redis缓存的作用。涉及的技术点包括:预读,局部性原理,LRU,预读失败+缓冲池污染,新生代老生代双链LRU
- 更改缓冲区(Change Buffer):为了插入或者更新次要索引而存在,是Buffer Pool的一部分,当辅助索引页不在缓冲池中时,更改缓冲区负责缓存对这些页的更改。
- 自适应哈希索引(Adaptive Hash Index):用于优化某些读取选项的性能。它旨在通过提供快速的内存查找机制来加速对频繁查询的索引页的访问,加速读请求,减少索引查询的寻路路径。涉及的技术点包括:聚集索引,普通索引,哈希索引;
- 日志缓冲区(Log Buffer):保存要写入事务日志的更改的内存区域,日志缓冲区通过在定期将日志刷新到磁盘上的重做日志之前将日志写入内存来提高性能,并提供了高并发与强一致性的折衷方案。涉及的技术点包括:redo log作用,流程,三层架构,随机写优化为顺序写,次次写优化为批量写;
文件区域:
- 系统表空间(System tablespace):用作更改缓冲区的存储区域。InnoDB 使用一个或多个数据文件作为系统表空间。ibdata1默认情况下,MySQL在数据目录中创建该文件。启动选项innodb_data_file_path决定系统表空间数据文件的大小和数量。
- 每表文件表空间(File-per-table tablespaces):存储 InnoDB 表的实际数据。当您使用 InnoDB 存储引擎创建新表时,InnoDB 将每个表及其关联索引存储在一个扩展名为 file-per-tablespace 的文件中.ibd。例如,如果您创建一个名为tbl_name的表,InnoDB 将在数据目录中tbl_name创建一个相应的 file-per-tablespace 数据文件。tbl_name.idb
- 通用表空间(General tablespaces):可以存储多个表的共享表空间。通用表空间都是使用该CREATE TABLESPACE语句创建的。当多个表共享相同的通用表空间时,通用表空间有助于减少内存中表空间元数据的重复。因此,与每表文件表空间相比,通用表空间具有潜在的内存优势。
- Undo表空间(Undo tablespaces):存储撤消日志,其中包含撤消事务的最新更改的信息。MySQL 有两个默认的撤消表空间文件innodb_undo_001 和innodb_undo_002.
- 临时表空间(Temporary tablespaces):当您创建临时表时,InnoDB 将它们存储在临时表空间中,更具体地说是会话临时表空间中。
- 双写缓冲区(Doublewrite buffer):InnoDB 使用 Doublewrite Buffer 来存储在实际写入 InnoDB 数据文件之前已从缓冲池中刷新的页面。允许 InnoDB 检索可靠的页面副本,以便在发生存储问题时进行恢复。
- 重做日志(Redo log):用于存储对表所做的更改。InnoDB在崩溃恢复期间使用重做日志来纠正不完整事务写入的数据。例如,当您执行更改数据库的 SQL 语句(例如INSERT、UPDATE和DELETE )时,重做日志会将请求存储在重做日志文件中。如果发生崩溃,MySQL 会重播重做日志中在接受连接之前未完成的修改。InnoDB 使用一组重做日志文件(ib_logfile0、iblogfile1、 …)来存储对表数据的更改。
- 撤消日志(Undo logs):存储回滚操作所需的信息。例如,如果您执行一个事务并决定回滚它,InnoDB将利用撤消日志来撤销该事务期间所做的更改。InnoDB 使用一组撤消日志文件(通常命名为undo_001.ibd、udo_002.ibd等)来存储日志。